Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Abstract
- Recurrence, Convolution 없이 Attention만 사용한 모델인 Transformer를 제안.
- SOTA 달성
- 큰 데이터나 제한된 데이터에도 다양한 task에서 일반화 성능 우수
Introduction
- 이전에는 주로 RNN 모델들이 사용 되었다. (LSTM, GRU)
- Recurrent 모델은
- 이는 본질적으로 병렬화가 불가능 하다는 의미가 됨.
(현재 상태를 만들기 위해 이전 상태가 필요하기 때문에 동시에 여러 state를 생성할 수 없기 때문)
Model Architecture

Encoder
- 6개의 동일한 layer로 구성되어 있다. (Figure 1에서 N=6) input이 첫 번째 layer이고, 현재 layer의 결과가 다음 layer의 input으로 들어가는 형태이다.
- 각 layer에는 2개의 sub-layer가 존재한다.
- multi-head self-attention
- fully connected feed-forward network
- 2개의 sub-layer 주위에 residual connection을 수행한 뒤, 정규화(normalization) 진행.
- 각 sub-layer의 출력은 LayerNorm(x + Sublayer(x))이고, 이러한 residual connection을 수행하기 위해 embedding dimension과 차원을 동일하게
Decoder
- Encoder와 같이 6개의 동일한 layer로 구성되어 있으며, residual connection 수행 후, 정규화를 진행하는 부분도 동일.
- Encoder와 다른 점은 각 layer에 2개의 sub-layer외에도 Encoder 결과에 multi-head self-attention을 수행하는 3번째 sub-layer가 추가된다는 점.
- Encoder와 달리 순차적으로 결과를 만들어 내야 하기 때문에 self-attention을 변형하여 사용한다. masking을 통해 position
위 예시를 보면 b를 예측할 때는 a에만 의존하고 b 이후에 있는 c는 masking을 통해 의존하지 않도록 해준다.
Attention
attention은 Output에 Query, (Key-Value)쌍을 매핑하는 것으로 설명할 수 있으며, Query, Key, Value, Output은 모두 벡터이다.
- Query
기존 Sequence에서 어떤 position과 유사한지 판단한다. - (Key-Value)
기존 Sequence의 정보를 갖는다. - Output
Value들의 가중치의 합. 각 Value에 할당 된 가중치는 Query, Key의 Compatibility function에 의해 계산된다.
Scaled Dot-Product Attention
논문의 attention을 Scaled Dot-Product Attention이라고 한다. input은
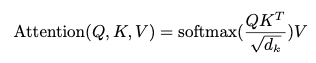
모든 Query, Key에 대한 내적(dot product)을 구한 뒤
- 실제로 논문에서는
- Key, Value 또한 각각
여기서
- Encoder-Decoder Attention에서
- Self-attention 에서
이해를 돕기 위해 attention 과정을 그림으로 살펴보자.
- Query, Key, Value가 다음과 같다고 가정 (1:1 Attention)

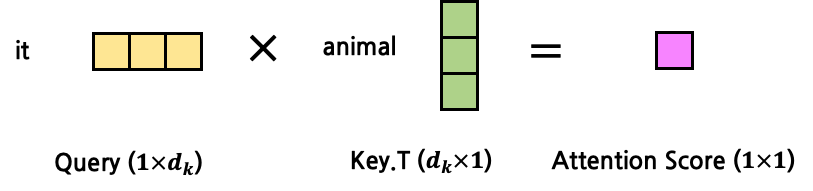
- 이를 1:N Attention으로 표현하면 다음과 같다.
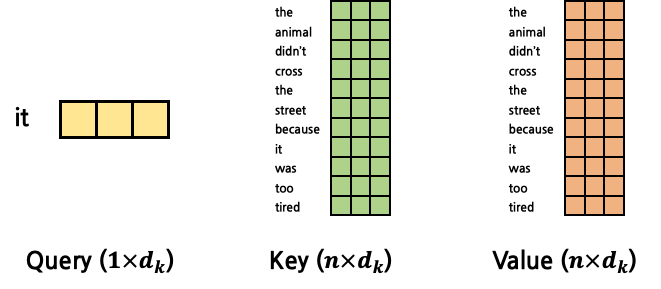
- 이들의 Attention Score
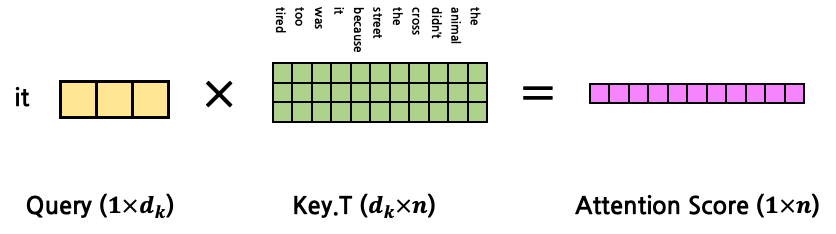
- 이를 이용해 Query Attention
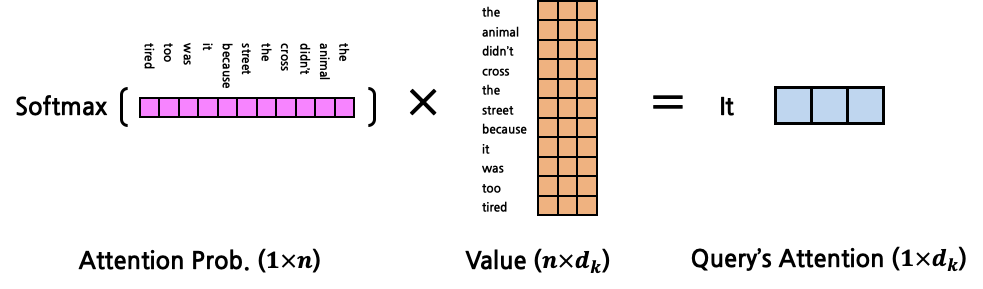
연산의 최종 output은 input과 같은 shape인 것을 확인할 수 있다.
- 이를 확장하여 모든 token에 대한 attention을 구할 수 있다. Query, Key, Value는 다음과 같다.
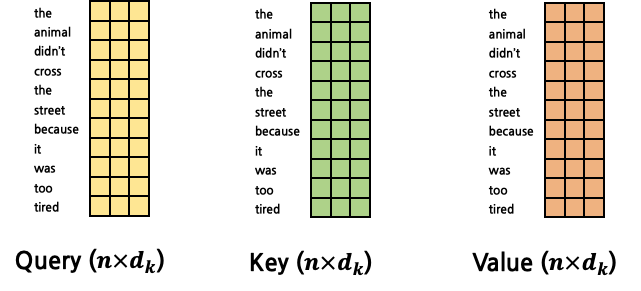
- 연산은 1:N Attention의 경우와 유사하다.
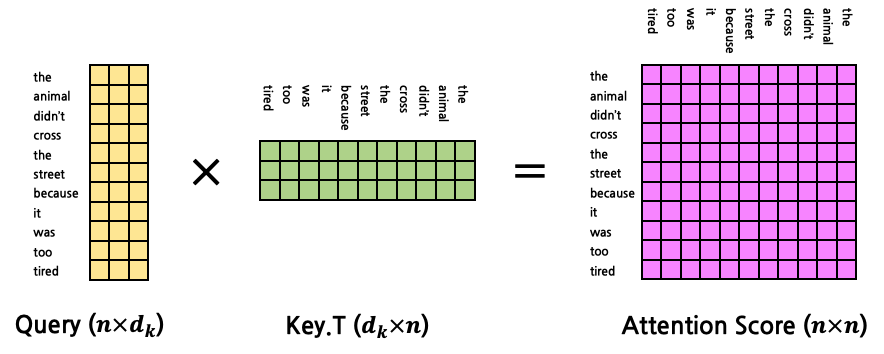
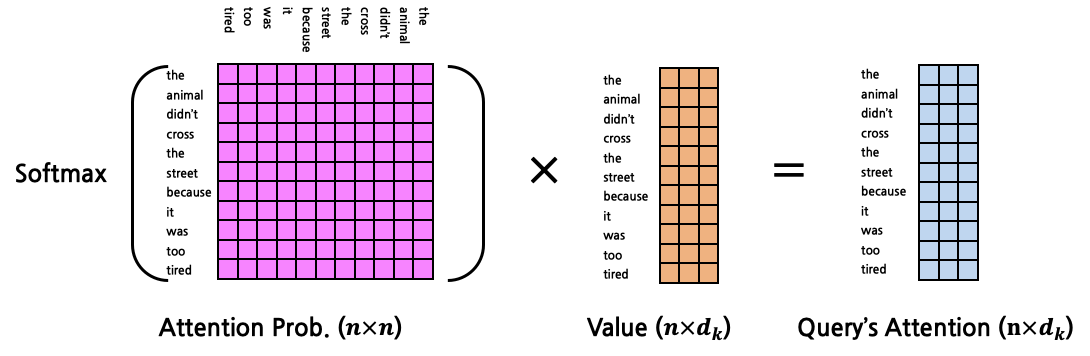
- 각각 서로 다른 FC Layer에 의해 구해진다.
- input은 word embedding vector들이고 output은
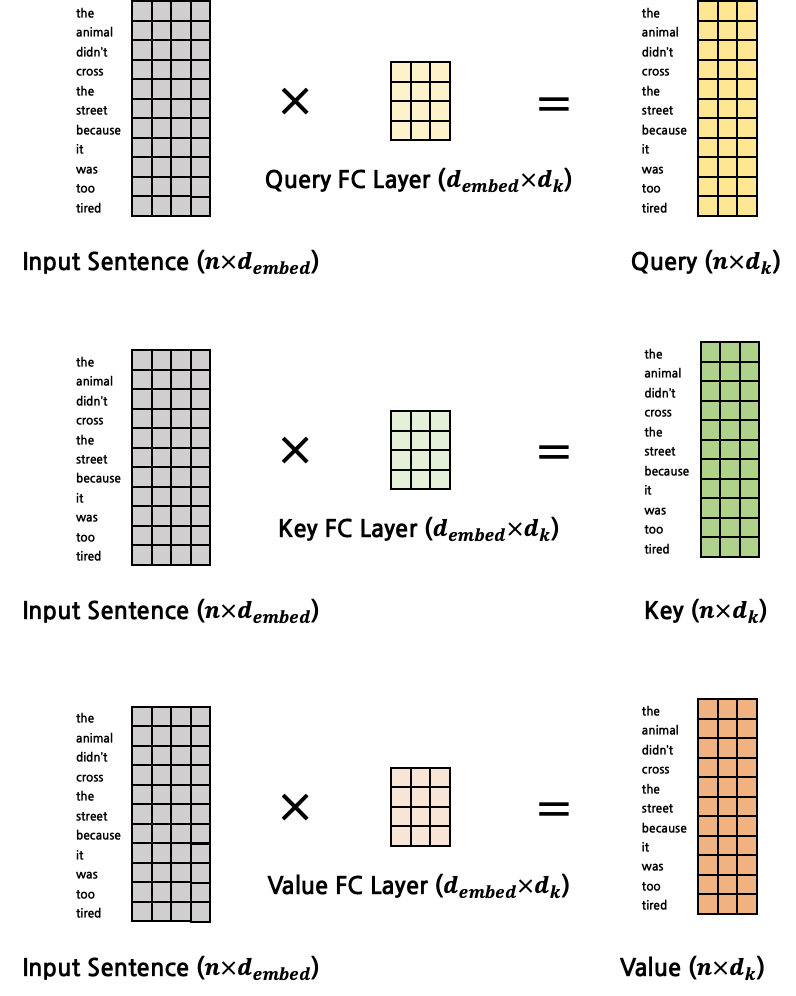
Multi-Head Attention
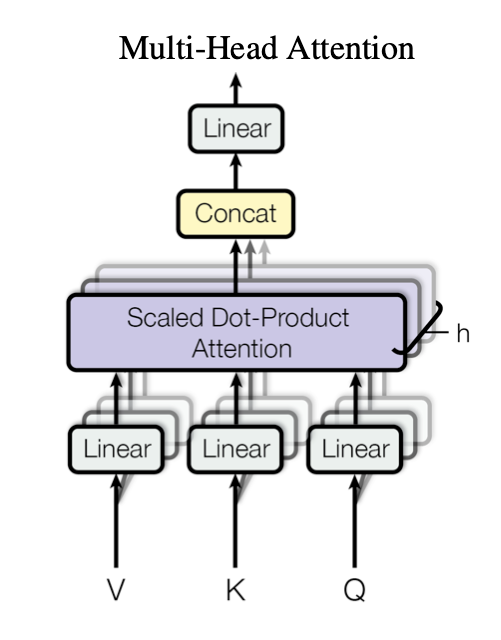
각 벡터들의 크기를 줄이고 병렬 처리가 가능하기 때문
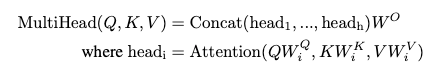
각각의 head 즉, Query, Key, Value를 h로 나눈 값들의 attention을 구하고 Concat한다.
(논문에서는
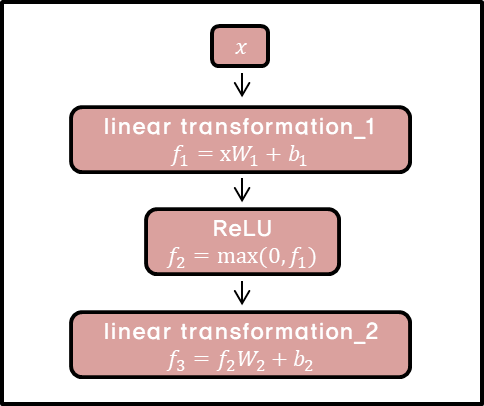
Position-wise Feed-Forward Networks
attention sub-layer 외에도, Encoder, Decoder의 각 Layer는 Fully Connected Feed-Forward Network를 포함하고 있다. 이는 ReLU를 활성 함수로 사용하는 두 개의 Linear transformations로 구성된다.
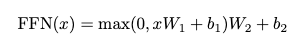
Postiional Encoding
Transformer는 RNN, CNN 계열이 아니기 때문에 모델이 sequence의 위치 정보를 사용하려면 위치 정보를 주입 해줘야 한다. 이를 위해 Encoder, Decoder 맨 아래에 있는 input embedding 부분에 positional encoding을 추가한다.
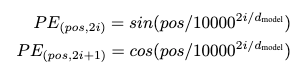
Why Self-Attention

- Layer 당 계산 복잡도가 줄어든다.
- 병렬 처리를 할 수 있는 계산의 양이 늘어난다.
- 네트워크 내의 먼 거리에 대한 종속성 path의 길이가 길다. 즉, RNN 계열 모델에 존재하던 Long Term Dependency 문제를 해결했다.
- Self-Attention (restricted)
sequence 길이 n이 클 경우, 전체에 대해 attention을 구하는 것이 아니라 size 'r'만큼의 주변만 계산한다.
Training
- Dataset
- WMT 2014 English-German
- WMT 2014 English-French
- Hardware
- NVIDIA P100 GPUs (8ea)
- Base model : 100,000 steps / 12 hours
- Big model : 300,000 steps / 3.5 days
- Optimizer
- Adam
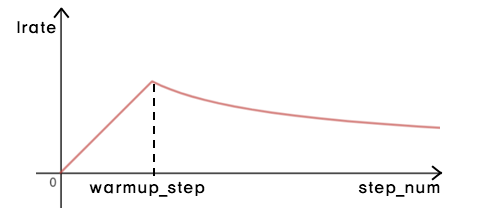
- Training 하면서 Learning rate를 다음 식에 따라 변화 시킴 (warmup_step = 4000)
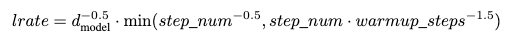
Regularization
훈련중에 3가지 유형의 정규화(Regularization)를 사용.
- Residual Dropout
- 각 sub-layer의 output마다 dropout적용(1)하며, 이는 정규화(normalization)전에 sub-layer input에 추가된다.
- embedding의 합, positional encoding에 dropout 적용(2). (Encoder, Decoder 모두에 적용)
- base model에서 dropout 비율은 0.1
- Label Smoothing
- 학습 동안 Label smoothing 적용
- 모델이 불확실한 것을 학습하므로 혼란을 야기한다고 생각할 수 있지만, 정확도와 BLEU Score는 향상됨.
- 학습 동안 Label smoothing 적용
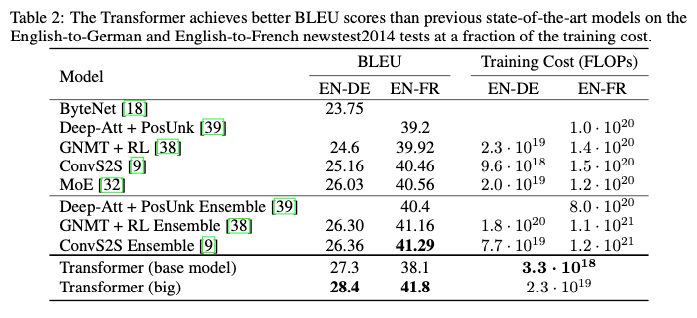
Results
📌 Reference
Attention is all you need paper 뽀개기
Transformer paper review
pozalabs.github.io
ATTENTION IS ALL YOU NEED 논문 리뷰
RNN이나 CNN이 아닌 새로운 구조를 개척한 Attention Is All You Need을 리뷰를 해보겠다. 특이한 구조를 가지고 있다. 한국어 리뷰1, 한국어 리뷰2, 논문을 참고하자. ABSTRACT sequence transduction models..
hipgyung.tistory.com
[NLP 논문 구현] pytorch로 구현하는 Transformer (Attention is All You Need)
Paper Link
cpm0722.github.io



