Custom data로 학습하는 방법은 아래 링크 참조
deep-text-recognition-benchmark (Custom Data로 학습하기)
GitHub - clovaai/deep-text-recognition-benchmark: Text recognition (optical character recognition) with deep learning methods. Text recognition (optical character recognition) with deep learning met..
ssun-g.tistory.com
Abstract
최근 STR 모델에 관한 새로운 제안들이 많이 소개 되었다. 각각의 주장들은 기술의 한계를 넘어 섰지만 데이터 셋이 제 각각이라 모델 간의 공정한 성능 비교가 불가능하다.
이를 해결하기 위해 크게 3가지 기여를 했다.
- train, evaluation 데이터셋의 불일치와 이로 인한 성능 차이 조사.
- 대부분의 기존 STR 모델에 적용할 수 있는 통합된 4 stage STR 프레임 워크를 소개.
- 일관된 training, evaluation 데이터셋에서의 정확성, 속도, 메모리 측면에서 성능에 대한 모듈 별 기여도 분석.
Introduce
STR은 다양한 산업 분야에서 매우 중요한 task이다. OCR 시스템의 발전으로 깨끗한 문서에 한해 좋은 성능을 보여주지만 대부분의 기존 OCR 방법은 STR에서 효과적이지 못한데, 그 이유는 다음과 같다.
- real-world에서 발생하는 다양한 텍스트 모양 (뒤집어져 있거나 글자의 배치가 원형이거나 등..)
- 캡처된 scene의 상태가 좋지 않음 (text가 일부 가려져 있거나 선명하지 않은경우)
이런 문제를 해결하기 위해 이전의 실험들은 multi-stage pipeline(각 stage는 특정 문제를 해결하는 deep neural network로 구성)을 제안. 예를 들어, 다양한 문자의 수를 처리하기 위한 RNN, 곡선으로 배치되어 있는 text를 직선으로 정규화 해서 처리하는 모델 등...
하지만 이런 다양한 모델들이 동일한 데이터를 사용한 것이 아니기 때문에 모델간의 성능 비교가 어렵다.
그래서 다음과 같이 제안한다.
1. 기존 STR 논문에 사용된 모든 training, evaluation dataset 분석.
- 여기서 모델마다 다른 dataset을 사용하는 것을 확인할 수 있다.
- 다음 표를 보면 빈칸(-)이 많은 것을 볼 수 있는데 이는 동일한 dataset에서 성능 비교를 할 수 없는 모델이 존재한다는 의미이다.기존 STR 논문에 사용된 모든 training, evaluation dataset 분석.

다른 dataset을 사용한 모델
그래서 다음 표와 같이 모든 dataset을 사용하여 성능을 비교했다.모든 dataset 사용
2. 기존 방법들에 대해 공통적인 관점을 제공하는 통합된 STR framework를 제안
- 특히 STR 모델을 4가지 연속적인 작업 단계로 나눔.
- Transformation
- Feature extraction
- Sequence modeling
- prediction
3. 통합된 실험 환경에서 Accuracy, Speed, Memory 측면에서 모듈 별 기여도 연구
- 이런 연구를 통해 개별 모듈의 기여도를 더욱 엄격히 평가하고 이전에 고려하지 않았던 모듈 조합을 통해 SOTA 급 모델모다 성능을 개선할 것을 제안한다.
Dataset Matters in STR
Synthetic datasets for training
실제 데이터를 labeling 하는 것은 비용이 많이 들어 얻기 힘들기 때문에 STR 모델의 학습에는 대체로 합성 이미지를 많이 사용한다. 따라서 최근 논문에서 가장 많이 사용 된 합성 이미지인 MJSynth / SynthText 두 가지를 소개한다.

- MJSynth (MJ)STR을 위한 합성 데이터 셋. Figure 1과 같은 word box 이미지가 8.9M개 존재한다. 생성 과정은 다음과 같다.
1. font rendering
2. border, shadow rendering
3. background coloring
4. composition of font, border, background
5. applying projective distortions
6. blending with real-world images
7. adding noise - SynthText (ST)
원래는 scene text detection을 위해 제작된 합성 데이터 셋. Figure 1에서 MJ와의 차이점을 확연히 알 수 있다. 해당 데이터에서 word box만 잘라서 STR에 사용했다고 한다. 알파벳이 아닌 문자들을 필터링 후, word box를 자른 뒤 STR task에 맞도록 구성하면 5.5M개의 이미지가 존재한다.
Real-world datasets for evaluation
7개의 real-world 데이터셋이 학습된 STR 모델을 평가하는데 널리 사용된다. Introduce 문단에서 사용한 Table 1 표를 보면 이전에 서로 다른 데이터셋으로 evaluation 한 것을 확인할 수 있다. 이러한 차이는 모델간의 성능 비교를 정확히 할 수 없음을 뜻한다. 그래서 우리는 Regular, Irregular dataset 두 가지 카테고리로 데이터셋을 구분할 것을 제안한다.
Regular dataset은 문자간의 간격이 일정하고 글자 배치가 가로로 된 경우를 뜻하며 다음과 같은 데이터셋이 존재한다.
- IIIT5K-Words (IIIT)
- Street View Text(SVT)
- ICDAR2003 (IC03)
- ICDAR2013 (IC13)
Irregular dataset은 curved, rotated, distorted 와 같이 변형이 있는 text 데이터를 뜻하며 다음과 같은 데이터셋이 존재한다.
- ICDAR2015 (IC15)
- SVT Perspective (SP)
- CUTE80 (CT)
STR Framework Analysis
논문에서 제안한 4 Stage로 구성된 STR framework를 소개하고 각 stage별 모듈을 자세히 설명한다.

1. Transformation stage (Trans.)
일상 생활에서 볼 수 있는 scene은 Figure 3과 같이 curved, tilted text인 경우가 많다. 이런 image를 downstream이 쉽도록 Spatial Transformer Network (STN) 의 변형인 Thin-Plate Spline (TPS)을 이용해 normalize 해주는 단계.
이 stage를 거치고 나면 text가 어느정도 올바르게 된다.(curved, tilted 등이 바르게 펴진다는 뜻) 모델 학습 시 TPS를 적용할지 말지 선택이 가능하다.
2. Feature extraction stage (Feat.)
Feat. stage는 CNN을 통해 input image를 추상화하고, visual feature map을 출력한다. VGG, RCNN, ResNet 세 가지로 실험을 했으며 Feat. 를 거치고 나면 image에서 Visual feature를 추출할 수 있고 이를
3. Sequence modeling stage (Seq.)
Seq. stage에서는 이전 단계인 Feat. stage에서 추출된 feature는 sequence 형태로 reshape 된다. 하지만 이 sequence는 context 정보가 부족하다. 그러므로 Bidirectional LSTM (BiLSTM)을 사용하여 context 정보를 갖고 있는 feature를 뽑아준다. 이를
4. Prediction stage (Pred.)
Pred. stage에서는 이전 단계인 Seq. stage에서 추출된
- Connectionist Temporal Classification (CTC)
- 고정된 수의 feature가 주어지더라도 고정되지 않은 수의 sequence를 예측할 수 있다.
- CTC의 핵심은 각 column에서 문자를 예측하고 반복 문자와 공백을 삭제함으로써 full character sequence를 non-fixed stream of character로 수정하는 것.
- Attention-based sequence prediction (Attn)
- 입력 sequence의 정보 흐름을 자동으로 캡처하여 출력 sequence를 예측한다.
- 이를 사용하면 STR 모델이 클래스 의존성을 나타내는 character-level language 모델을 학습할 수 있다.
Experiment and Analysis
해당 section에서는 4 stage framework에서 가능한 모든 모듈의 조합에 대한 평가 및 분석을 진행한다. 모든 조합의 수는 다음과 같다.
- Trans. : TPS / None (2)
- Feat. : VGG / RCNN / ResNet (3)
- Seq. : BiLSTM / None (2)
- Pred. : CTC / Attn (2)
(2 * 3 * 2 * 2 = 24 )
1. Implementation detail
STR training and model selection
공정한 성능 비교를 위해 데이터 셋을 동일하게 한 후 실험을 할 것. training dataset은 MJSynth / SynthText 2가지를 결합해 사용함.
<실험 환경>
optimizer: AdaDelta
training batch size: 192
iterations: 300K
gradient clipping: 5
모든 파라미터는 He로 초기화
validation data로는 IC13, IC15, IIIT, SVT를 결합하여 사용했고, IC03은 IC13과 중복되는 부분이 있어서 사용하지 않는다.
Evaluation metrics
- 데이터의 정확성을 체크하기 위해 벤치마크의 모든 데이터를 포함하는 9개의 실제 데이터셋으로 이미지당 예측 성공률을 측정한다.(알파벳, 숫자로만 평가)
- 각 STR 조합에 대해서 random seed로 5번의 실험을 한 뒤, 정확도의 평균으로 성능을 측정한다.
- 속도 측정을 위해 동일한 컴퓨터 실험 환경에서 이미지당 평균 clock time(ms)를 측정한다.
- 메모리 측정을 위해 전체 STR pipeline에서 훈련 가능한 부동 소수점 parameter의 수를 측정한다.
모든 평가에 사용된 실험 환경은 다음과 같다.

2. Analysis on training datasets
다른 그룹의 training dataset을 사용하여 성능에 얼마나 영향을 끼치는지 조사한다.
- MJSynth 사용시 정확도 80.0%
- SynthText 사용시 정확도 75.6%
- MJSynth + SynthText 사용시 정확도 84.1%
MJSynth 데이터와 SynthText는 distortion, blur 등 다른 옵션으로 생성된 데이터이기 때문에 서로 다른 속성을 가진다. 위 실험 결과와 데이터셋의 속성이 다르다는 특징을 바탕으로 모델이 학습할 때, 데이터의 양보다 질(다양한 데이터)이 중요하다는 것을 알 수 있다.
3. Analysis of trade-offs for module combinations
모듈간의 다양한 조합에 따라 (정확도-속도), (정확도-메모리) 간의 trade-off가 발생할 수 있는데 이에 집중한다.
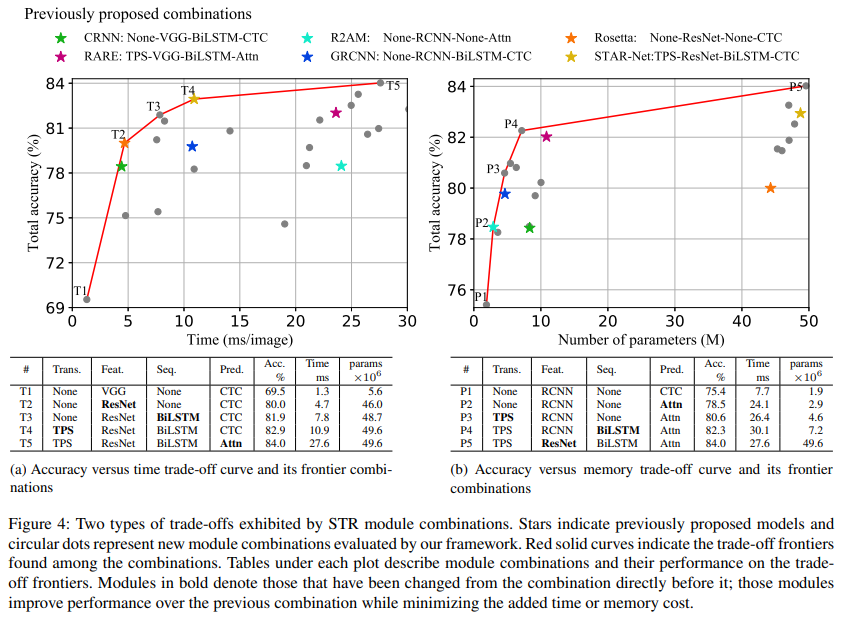
위 Figure 4를 보면 기존에 제안 되었던 6개의 모델 뿐만 아니라 본 논문에서 제안한 STR framework의 24가지 조합의 성능까지 확인할 수 잇다. 모듈 조합은 정확도 순으로 오름차순 네이밍 되었다.
Figure 4의 (a)는 (정확도-시간)의 trade-off를 실험한 것. 한 가지만 변경하면서 실험을 차례대로 한 것을 볼 수 있고, T4까지 성능 향상 효율이 좋은 반면 T4에서 T5로 변경 되었을 때는 효율이 좋지 않은 것을 볼 수 있다. (정확도가 1.1% 증가한 것에 비해 수행 시간이 16.7초나 늘어났다!)
Figure 4의 (b)는 (정확도-메모리)의 trade-off를 실험한 것. 한 가지만 변경하면서 실험한 결과 위와 동일하게 P4까지는 성능 향상 효율이 좋은 반면 P5에서는 효율이 좋지 못한 것을 확인할 수 있다. 메모리 사용을 줄이기 위해 ResNet과 같은 무거운 모델을 사용하는 것을 지양해야 한다.
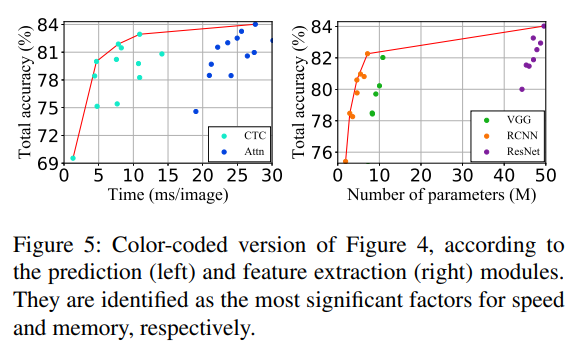
Figure 5의 오른쪽 표를 보면 Feature extraction 모델에 따라 성능의 변화가 가장 큰 것을 알 수 있다.
4. Module analysis
해당 section에서는 모듈별 accuray, speed, memory를 조사한다. 실험 결과는 다음과 같다.
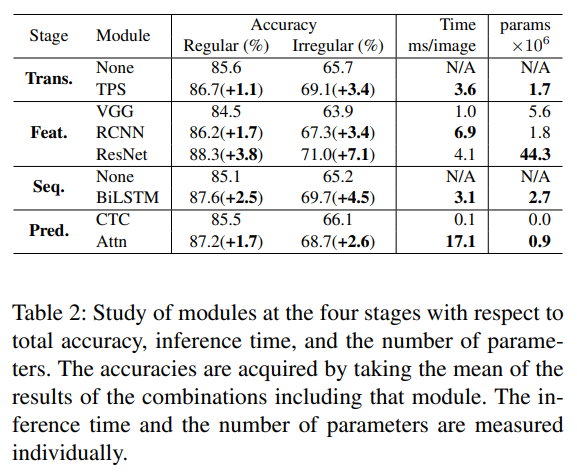
Table 2를 보면 성능 향상을 위해 메모리(Params) 또는 수행 시간(Time)의 증가는 불가피하다는 것을 알 수 있다.
- 기본 모듈은 None - VGG - None -CTC 이다.
- (정확도-시간) 측면에서는 Resnet - BiLSTM - TPS - Attn 순으로 모듈을 교체하는 것이 가장 효율이 좋다.
- (정확도-메모리) 측면에서는 RCNN - Attn - TPS - BiLSTM 순으로 모듈을 교체하는 것이 가장 효율이 좋다.

Figure 7은 기존 STR 모델에서 제대로 인식할 수 없었던 text의 예시이며, 각 모듈이 어느 부분에서 기여하는지 볼 수 있다.
- TPS: curved text를 잘 인식할 수 있다.
- ResNet: 배경 때문에 잘 보이지 않는 text를 잘 인식할 수 있다.
- BiLSTM: 잘려진 text를 잘 인식할 수 있다.
- Attn: 가려져 있는 text를 잘 인식할 수 있다.
5. Failure case analysis
24개의 모듈 조합을 모두 실험했음에도 불구하고 잘 인식하지 못했던 사례들을 소개한다. 즉, 이러한 사례들은 STR 분야의 challenge가 될 것.

Figure 6은 인식에 실패한 사례를 카테고리 별로 확인할 수 있다. 전체 데이터셋(8539개)에서 644개의 이미지(약 7.5%)는 어떤 모듈도 올바르게 인식하지 못했다고 한다.
Conclusion
STR 모델이 크게 발전했지만 모두 다른 데이터셋에서 성능을 비교해왔다. 그래서 제안된 모듈이 STR baseline model을 효과적으로 개선할 수 있는지 결정하기 힘들었다. 이런 문제를 해결하기 위해 주요 STR 방법들과 일관된 데이터셋들(7개의 벤치마크 평가 데이터셋, 2개의 학습 데이터셋(MJ, ST)) 간의 공통 프레임 워크를 제안했다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] DETR: End-to-end Object Detection with Transformers (0) | 2022.08.22 |
|---|---|
| [논문 리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.05.26 |
| [논문 리뷰] Attention Is All You Need (0) | 2022.05.19 |
| [논문 리뷰] CoAtNet: Marrying Convolution and Attention for All Data Sizes (0) | 2022.01.24 |
| [논문 리뷰] EfficientDet: Scalable and Efficient Object Detection (0) | 2022.01.21 |



