An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Abstract
Vision에서 ViT이전에는 attention을 다음 2가지 방식으로 사용했다.
- CNN과 함께 결합되어 사용.
- CNN의 특정 요소를 대체하여 사용
본 논문에서는 CNN이 필수가 아니고 Transformer만으로 이미지 분류가 가능하며 성능 또한 우수하다는 것을 보여준다.
그 결과로 당시 SOTA를 달성했으며, 또한 CNN 계열 모델에 비해 Computational resource 대체로 적게 든다고 한다.
Introduction
- Self-attention 기반의 Transformer는 NLP에서 가장 대표적인 모델이다.
- 그 중 BERT라는 모델은 Large text corpus(큰 데이터셋)로 사전학습(Pre-train) 한 뒤, Smaller task-specific dataset(작은 데이터셋)으로 미세조정(Fine-tune) 한다.
- Transfomer의 장점
- 계산의 효율성(Computational efficiency), 확장성(Scalability)이 좋다.
- 100B parameter라는 전례 없이 큰 크기의 모델을 학습하는 것이 가능해졌다.
- 데이터셋이 커져도 성능이 포화될 징후를 보이지 않는다.
→ 모델의 사이즈를 키울수록 성능이 계속 좋아짐.
Vision에서의 Transformer 적용
- 이미지를 여러 개의 patch로 분할 후, 이에 대한 선형 embedding sequence를 Transformer에 입력.
- NLP에서 Transformer가 token을 입력으로 받는 방식과 동일하다. (여기서 token = image patch)
- Supervised Learning
특징
- ImageNet과 같은 mid-size의 데이터셋에 대해서는 비슷한 크기의 ResNet보다 성능이 떨어진다.
- Transformer는 inductive biases가 존재하지 않기 때문에 Translation equivariance, Locality와 같은 CNN의 특성을 가지고 있지 않다.
- 그래서 충분한 양의 데이터셋이 아니라면 학습이 잘 되지 않는다.
- 충분한 양의 데이터셋으로 학습시 Transformer의 성능이 더 우수하다.
Method
가능한 Original Transformer와 유사한 구조를 따르도록 모델을 설계함.

Vision Transformer (ViT)
Input Embedding
- Standard Transformer는 토큰 임베딩을 1D sequence로 입력 받음.
- 2D 이미지를 Transformer에 입력하기 위해 1D sequence 형태로 변환해야 함.
- 2D 이미지
- 2D 이미지
- 예시) 이미지 크기가 224*224이고, 패치의 크기가 16*16인 경우
- Transformer는 모든 레이어에서 size
이 출력을 Patch Embedding이라 한다.
[class] token
- BERT의 [class] 토큰과 비슷하게, Embedded patch
- pre-training, fine-tuning을 수행하는 동안 Classification head는
- Classification Head란...
- pre-training : 1 hidden layer MLP
- fine-tuning : 1 linear layer
Position Embedding
- position embedding은 위치 정보를 유지하기 위해 patch embedding에 추가된다.
- 2D-position embedding을 사용해봤지만 확실한 성능 향상이 관찰되지 않음.
→ 그래서 1D-position embedding을 사용했다! - 임베딩 벡터의 결과 Sequence는 Encoder의 입력이 된다.
Transformer
- Encoder는 Multi-headed self-attention(MSA)과 MLP 블록이 교대로 구성되어 있다.
- 모든 블록 이전에 LayerNorm(LN)을 적용한다.
- 모든 블록 이후에 Residual Connection을 적용한다.
- MLP는 GELU non-linearity를 포함한 두 개의 레이어로 구성되어 있음.
Inductive bias
- ViT는 CNN과 다르게 이미지 별 Inductive bias가 부족함.
- ViT는 MLP layer만 Locality, Translationally equivariant 특성을 가지고 Self-attention은 Global한 특성을 가진다.
- 2차원 구조는 매우 드물게 사용한다.
- 이미지를 Patch로 자르는 부분에서 사용.
- Fine-tuning 시, 다른 해상도 이미지를 위한 Positional embedding을 조정할 때 사용.
- Position embedding 초기화 시, 각 patch의 2D 위치에 대한 정보는 전달되지 않고 patch간의 모든 공간 관계를 새로 학습해야 한다.
Hybrid Architecture
- Image patch의 대안으로 CNN에서 추출된 feature map을 sequence로 입력할 수 있음.
- 하이브리드 모델에서는 CNN으로부터 추출된 feature map에 embedding projection
- 특이 케이스로 CNN feature map은 spatial size가 1x1이 될 수 있다.
→ 이는 단순히 공간 차원을 평면화(flatten)하고 Transformer 차원으로 projecting하는 것으로 input sequence를 얻을 수 있다는 것을 의미한다.
Fine-Tuning & Higher Resolution
- 일반적으로 ViT는 큰 데이터셋에서 사전학습(pre-train) 후, downstream task(작은 데이터셋)에서 미세조정(fine-tune)한다.
- 사전학습 때보다 높은 해상도로 미세조정 하는 것이 성능 향상에 도움이 된다.
- 높은 해상도의 이미지에서 동일한 patch size를 가진다면 sequence length가 길어지기 때문이다. 즉, patch의 수가 증가한다는 의미.
- 미세조정시 사전학습된(pre-trained) position embedding은 의미가 없기 때문에 원본 이미지 위치에 따른 position embedding에 2D 보간법(interpolation)을 수행한다.
Experiments
Dataset
- ImageNet (1K classes & 1.3M images)
- ImageNet (21K classes & 14M images)
- JFT (18K classes & 303M high resolution images)
Model Variants
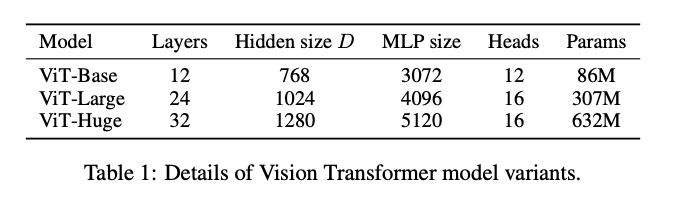
Training & Fine-Tuning
- Pre-training
- optimizer : Adam
- batch size : 4096
- weight decay : 0.1
- optimizer : Adam
- Fine-tuning
- optimizer : SGD + Momentum
- batch size : 512
Comparison to State Of The Art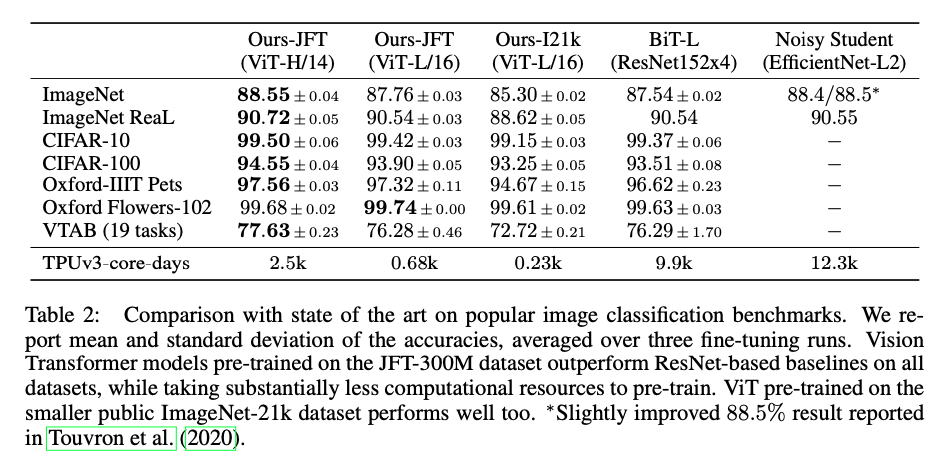
Pre-training Data Requirements
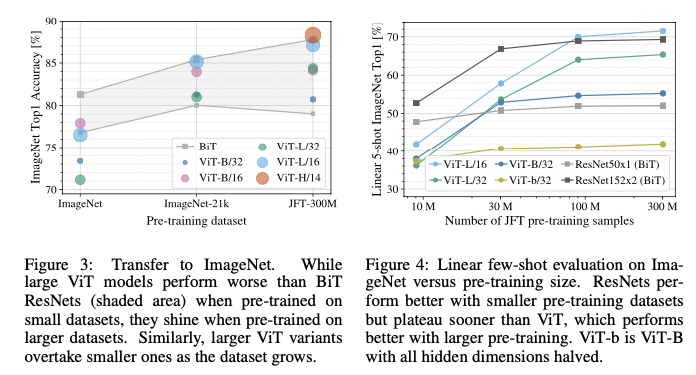
- 데이터셋이 클수록 (ImageNet → ImageNet21k → JFT-300M) ViT의 성능이 좋다. --- Figure 3
- 작은 데이터셋으로 학습시 성능은 좋지 않다. --- Figure 4
📌 Reference
[논문요약] Vision분야에서 드디어 Transformer가 등장 - ViT : Vision Transformer(2020)
*크롬으로 보시는 걸 추천드립니다* https://arxiv.org/pdf/2010.11929.pdf 종합 : ⭐⭐⭐⭐ 1. 논문 중요도 : 5점 2. 실용성 : 4점 설명 : 게임 체인저(Game Changer), Convolutional Network구조였던 시각 문제..
kmhana.tistory.com
Vision Transformer (2)
지난 포스트 [Machine Learning/Vision] - Vision Transformer (1) Experiments How fine-tuning 실험 시에는 ViT 모델을 큰 데이터셋에 대해 사전훈련 하고 작은 데이터셋에 대해 fine-tuning 하는 과정을 거칩니..
hongl.tistory.com



