End-to-End Object Detection with Transformers
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor gene
arxiv.org
DETR Architecture
CNN Backbone + Transformer + FFN(Feed Foward Network)로 구성되어 있다.

CNN Backbone
- input image → CNN Backbone 통과 → feature map 생성
- transformer에 들어갈 수 있도록 처리 해준다.
- feature map의 shape은 (C*H*W). (ResNet50이 Backbone이므로 C=2048)
- 1x1 Convolution을 적용해 shape를 (d*H*W)로 변경한다. (C > d)
- transformer의 입력 shape는 2차원 형태이므로 (d*H*W) → (d*HW)의 2차원으로 구조를 변경한다.
Transformer

Encoder
[파란 박스]
feature map + positional encoding 정보를 더한 matrix를 multi-head-self-attention에 통과
Decoder
[분홍 박스]
N개의 bounding box에 대해 N개의 object query를 생성. 이 값의 초기 값은 0이다.
[보라 박스]
분홍 박스에서 생성된 N개의 object query를 입력 받아 multi-head-self-attention을 거쳐 가공된 N개의 unit을 출력한다.
[노란 박스]
보라 박스를 통과해 나온 N개의 unit들이 Query로 입력되고, Encoder의 출력 unit들이 Key, Value로 입력되어 encoder-decoder multi-head-attention을 수행한다.
[녹색 박스]
FFN을 거쳐 object class와 box 정보를 출력.
FFN(Feed Forward Network)
Transformer의 결과로 나온 N개의 unit은 FFN을 통과하여 class와 bounding box의 크기, 위치를 동시에 예측한다.
이 때, bi-partite matching을 통해 bounding box가 겹치지 않도록 한다.
Original Transformer와 다른 점

- Positional encoding 하는 위치가 다름 (빨간 원)
- Auto-regression이 아닌 Parallel 방식으로 output 출력.
- 기존 Transformer의 방식인 Auto-regression은 단어 한 개씩 순차적으로 출력한다. 현재 output 값을 출력하기 위해 이전 단계까지 출력한 output을 참고하는 방식.
- DETR의 방식인 Parallel 방식은 모든 output을 한 번에 출력하는 방식.

Bipartite Matching
DETR은 충분히 큰 수의 bounding box를 N개 설정하고, 이에 대해서 class와 bounding box의 크기 및 위치를 예측한다.
예를 들어, 아래 그림처럼 N=4이고 이미지에 2개의 object만 존재한다면, 2개의 bounding box를 예측하게 되고 나머지에 대해서는 no boject를 출력한다.

하지만 DETR은 Parellel 방식으로 output을 출력하므로 N개의 bounding box가 어떤 ground truth object를 검출하고 있는지 알 수 없다는 것이 단점이다.
- 위 그림에서 분홍색 bounding box가 1번 object에 대한 bounding box 였다면 loss 값이 작겠지만, 2번 object에 대한 bounding box 였다면 loss 값이 클 것이다.
- 따라서, bounding box가 어떤 object를 검출하는지 1:1로 매칭을 해줘야 하는데, 이 과정이 bipartite matching이다.
Loss function & Training
\(\sigma\) : Ground truth의 object set의 순열
\(\hat{\sigma}\) : \(\mathcal{L}_{match}\) 를 최소로 하는 예측 bounding box set의 순열
\(y\) : Ground truth의 object set
\(\hat{y}\) : 예측한 N개의 object set
\(c\) : class label
\(b\) : bounding box의 위치와 크기 (\(x, y, w, h\))
\(\mathcal{L}_{match}\)
ground truth의 bounding box와 예측 bounding box가 잘 매칭 되었을 때 낮은 값을 가지도록 한다.

1-1. [빨간 박스] \(\hat{p}_{\sigma(i)}(c_i)\)
해당 class로 모델이 예측한 확률. 앞에 음수(-)가 붙어 있으므로 해당 확률이 높을수록 \(\mathcal{L}_{match}\) 값은 작아진다.
1-2. [파란 박스] \(\mathcal{L}_{box}\)
- ground truth의 bounding box와 예측 bounding box 사이의 loss.
- bounding box의 크기가 클수록 L1 Loss가 커지기 때문에 다음과 같이 bounding box간 IOU Loss를 더하여 이를 보정해준다.

\(\hat{\sigma}\)
\(\mathcal{L}_{match}\)를 최소로 하는 예측 bounding box 순서를 찾는다.

Hungarian Loss
해당 Loss를 최소화 하는 방향으로 학습이 진행 됨.
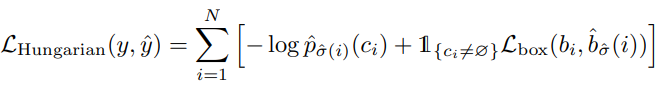
장점
- Transformer를 object detection에 최초로 적용.
- COCO dataset에서 Faster R-CNN baseline 급의 정확도와 런타임 성능을 보여준다.
- End-to-End training이 가능함.
- 간단 명료한 구조 + 깔끔한 코드
단점
- Transformer의 특성 상 학습 하는데 시간이 오래 걸림.
- small object detection 성능이 떨어짐.



